What's Data Quality Studio
Data Quality Studio is Atlan's native data quality module that enables business and data teams to collaborate on defining, monitoring, and enforcing data quality expectations directly within the Atlan platform.
Unlike disconnected scripts or external tools that create blind spots in data pipelines and delay issue detection, Data Quality Studio embeds quality checks into your warehouse and surfaces trust signals across Atlan—where your teams already work.
Core components
Rule
SQL-based expectation about your data
Rule set
Group of related rules applied to a table
Check run
Execution of rules in your warehouse
Status
Result: passed, failed, or warning
Trust signals
Visual indicators and alerts in Atlan
Key capabilities
Define expectations
Create data quality rules using familiar SQL logic that reflects your business requirements
- SQL-based rule authoring
- Versioned execution and history tracking
- Multi-rule validation per dataset
Execute checks
Run quality checks where your data lives, directly in the warehouse using native compute
- BigQuery: Stored procedures for rule execution
- Databricks: Delta Live Tables execution
- Snowflake: Data Metric Functions (DMFs)
- Push-down execution model
Surface trust
Display quality signals across Atlan through warnings, trust scores, and notifications
- Trust scoring and visual feedback
- Alerting and integrations
- Query-based diagnostics for failed rules
Centralized management
Manage all data quality rules and monitoring from a single platform interface
- Centralized rule management
- Cross-team collaboration
- Integrated with existing workflows
This helps build a proactive, transparent culture of data trust across your organization.
How it works
Data Quality Studio uses a push-down execution model. Rules are defined through Atlan's interface and executed natively in your data warehouse without needing additional infrastructure.
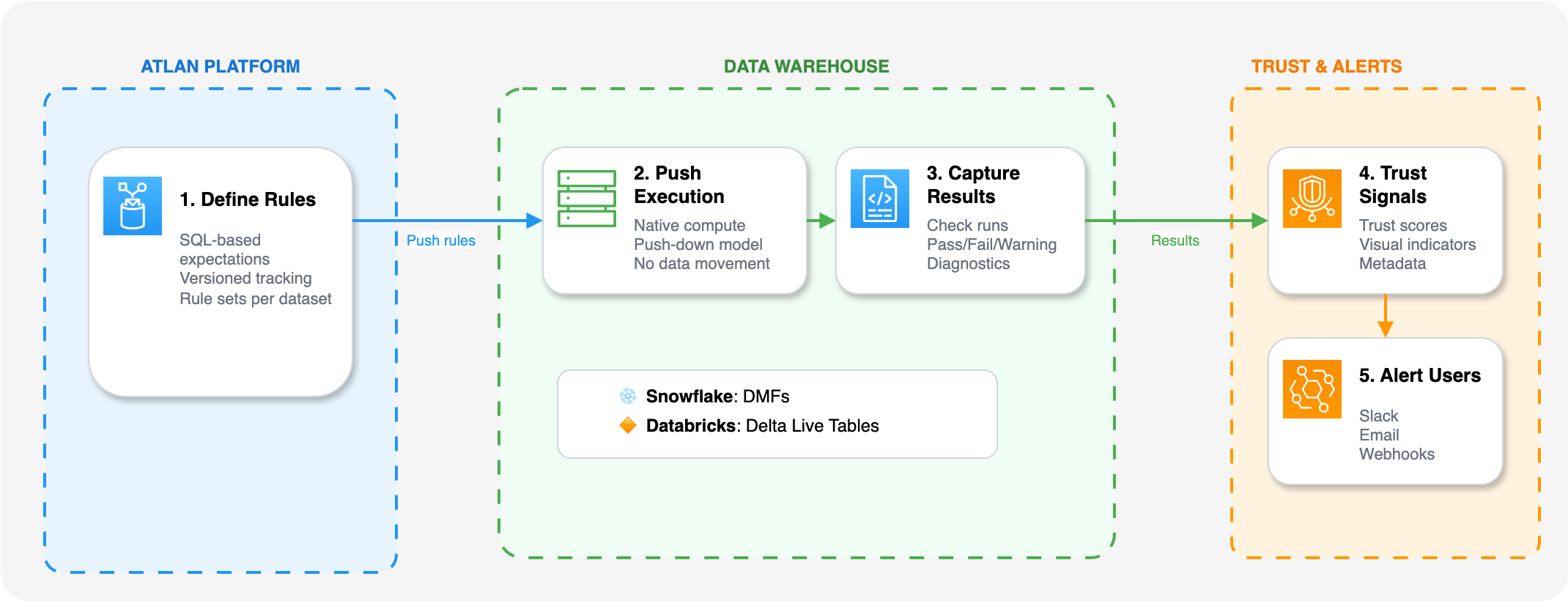
The flow follows these steps:
1. Define rule sets: Using SQL logic that reflects your data expectations. Rules are grouped into rule sets, typically applied to a table or dataset. With versioned execution and history tracking, you can track changes and rollback if needed.
2. Push execution to your warehouse: This triggers native compute in your environment:
- BigQuery executes rules via stored procedures
- Databricks leverages Delta Live Tables for rule execution
- Snowflake executes rules via Data Metric Functions (DMFs)
3. Capture results: As check runs with pass, fail, or warning statuses. Query-based diagnostics help investigate failed rules.
4. Surface signals: Through trust scores, visual indicators, and metadata in Atlan. Trust scoring and visual feedback appear across the platform.
5. Notify users: Using alerts and webhooks when checks fail or thresholds are breached.
This system ensures quality checks are versioned, repeatable, and integrated into your data stack. Because execution happens in your warehouse, you can validate entire datasets—billions of rows if needed—without moving data or maintaining separate infrastructure. The results flow back to Atlan, where they become part of your data's metadata, visible wherever teams interact with data assets.
See also
- Rule types and failed rows validations: Reference guide for all available rule types and how failed rows validation works
- Rules and dimensions reference: Explore all supported rule types, dimensions, and examples
- Advanced configuration: Set up notifications for failed rules and threshold breaches
- Configure webhooks: Send data quality rule events to an external endpoint