Architecture
The Lakehouse is an open, interoperable data lakehouse platform that makes all of your Atlan metadata instantly available to power reporting and AI use cases. The architecture uses Apache Iceberg table format, Apache Polaris catalog, and cloud object storage to provide queryable access to your metadata through any Iceberg REST-compatible client.
Layered architecture
Lakehouse follows a layered architecture, consisting of three primary components:
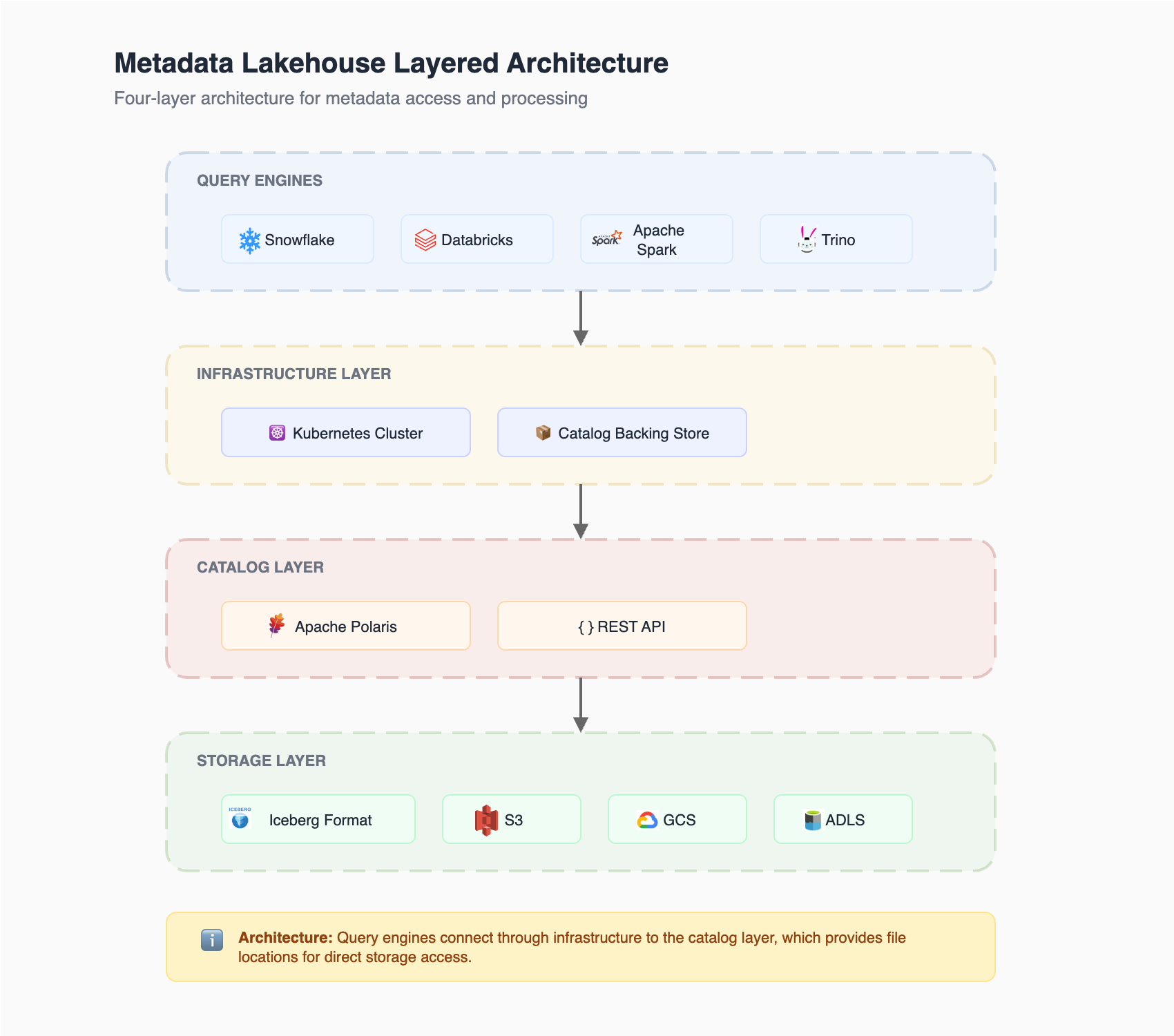
Infrastructure layer
The lakehouse catalog infrastructure is deployed via Kubernetes in an Atlan-managed cloud account:
- Kubernetes deployment: Catalog backing store and related infrastructure run on Kubernetes
- Cloud provider alignment: Infrastructure matches the Atlan tenant's cloud provider:
- AWS tenants → EKS cluster in Atlan's AWS account
- GCP tenants → GKE cluster in Atlan's GCP account
- Azure tenants → AKS cluster in Atlan's Azure account
Catalog layer
An Atlan-managed lakehouse catalog serves as the entry point for engines to query the metadata lakehouse:
- Built on Apache Polaris: Implements the Iceberg REST Catalog API
- Compatible clients: Any client supporting Iceberg REST Catalog API can query the metadata lakehouse (Snowflake, Trino, Presto, Spark)
- Query time behavior: The catalog provides locations of data files to retrieve for executing queries
- No data duplication: Data isn't duplicated when clients query the catalog
Storage layer
All files for a customer's Lakehouse reside in an Atlan-managed object storage bucket:
- One bucket per tenant: Each tenant has a dedicated object storage bucket
- File types: Stores both Iceberg metadata files (metadata files, manifest lists, snapshots) and Parquet data files
- Encryption: Data is encrypted at rest using the object storage service's default encryption
- Cloud alignment: The object storage service depends on your Atlan tenant's cloud provider:
- GCP tenants → Google Cloud Storage (GCS)
- Azure tenants → Azure Data Lake Storage (ADLS)
- AWS tenants → Amazon S3
How queries are processed
The architecture uses a dual-connection pattern that separates metadata operations from data operations. Query engines establish two independent connections:
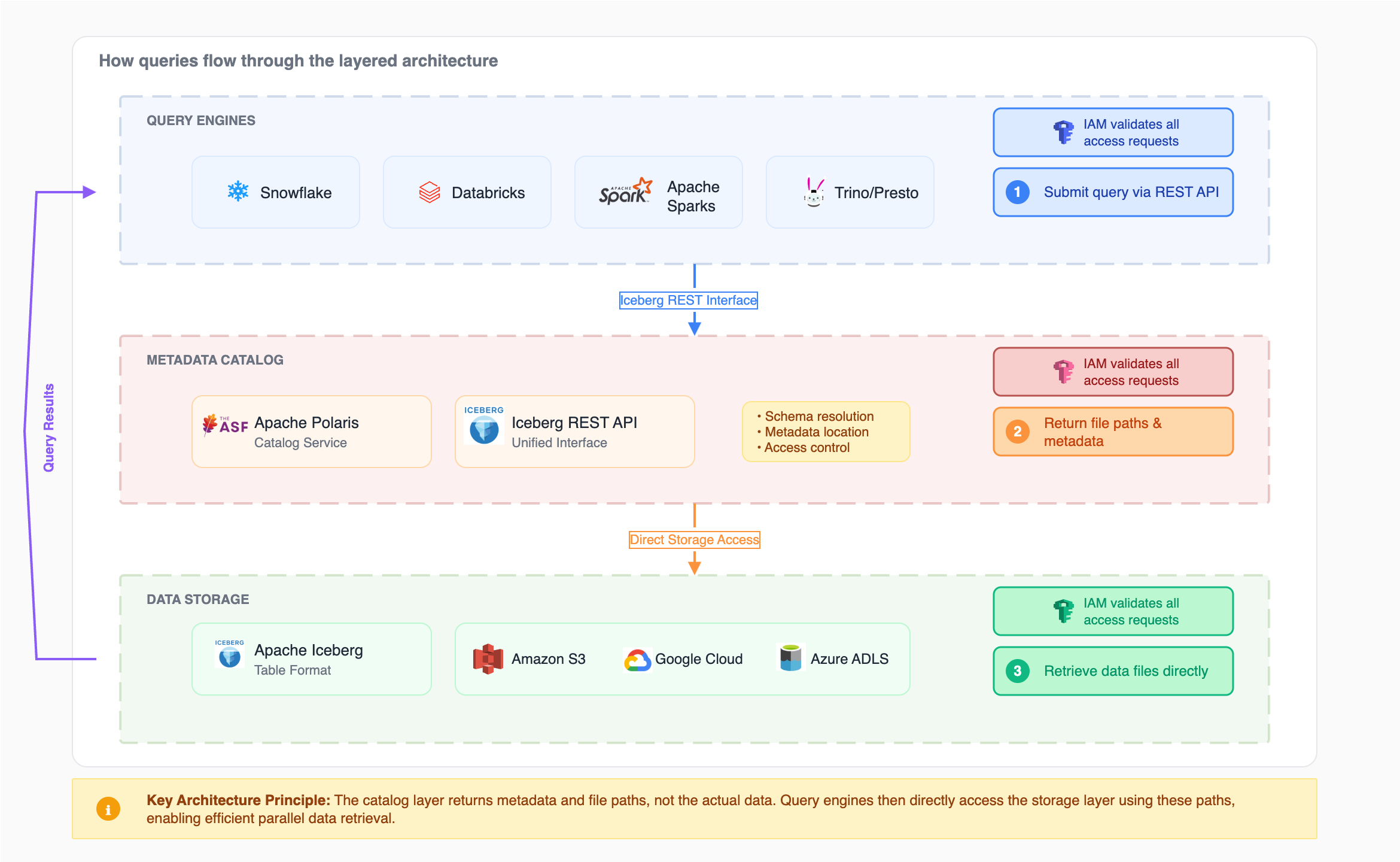
- Catalog connection: For metadata operations—discovering tables, resolving schemas, and retrieving file locations via the Iceberg REST API
- Storage connection: For data operations—reading Parquet files and Iceberg metadata files directly from object storage
This separation enables the following query flow:
-
Catalog interaction: The query engine submits a query to the catalog through the Iceberg REST API. The catalog returns the locations of data files in object storage that contain the requested data. No actual data transfers at this stage—only file pointers.
-
Direct storage access: The query engine connects directly to object storage using the file locations provided by the catalog. The cloud provider validates access using identity and access management policies (for example, AWS IAM policies, GCP IAM, or Azure RBAC). Once authorized, the engine retrieves and processes the data files.
For example, when Snowflake queries the Lakehouse, it first contacts the catalog to retrieve S3 file locations, then directly accesses S3 where AWS validates the request with the available IAM policies before granting access.
This architecture decouples metadata management from data access, allowing the catalog to remain lightweight while enabling high-performance parallel data retrieval. Multiple engines can query the same data simultaneously without conflicts or data duplication.
See also
- Security: Security model and access controls
- Automated maintenance: Table maintenance and optimization